-
ShMarket - 조회 성능 최적화 기록기ShMarket 2021. 6. 21. 22:13
프로젝트 개발 중 적은 수의 더미 데이터로 테스트를 하던 중
사용자가 많아져 상품, 커뮤니티 ( 게시글 )가 많아진다면 성능 이슈가 발생하지 않을까라는 생각에
나름 대용량 데이터를 넣고 성능을 비교해가며 개선 과정을 기록한 포스팅입니다.
테스트 데이터 : 백만 개 기준
대상 : Board, Product 중 Board로 포스팅을 진행합니다.
Board.java
public class Board { ...// @OneToMany(mappedBy = "board", cascade = CascadeType.ALL) private Set<Comment> comments = new LinkedHashSet<>(); @OneToMany(mappedBy = "board", cascade = CascadeType.ALL) private Set<BoardAlbum> boardAlbums = new LinkedHashSet<>(); @ManyToOne(fetch = FetchType.LAZY) private Member member; }기존 조회 로직 Service
먼저 조회는 3가지의 조건에 맞춰 진행됩니다.
1. 원하는 카테고리의 게시글만 출력
2. 자신 주변 동네의 게시글만 출력
3. 차단한 사용자의 게시글을 출력하지 않음
즉 카테고리, 주변 동네, 차단 3가지의 필터링을 거쳐 다음과 같이 진행됩니다.
public List<BoardListResponseDto> findAllBoardByCategory(List<String> categories) { StopWatch stopWatch = new StopWatch(); stopWatch.start(); String username = SecurityContextHolder.getContext().getAuthentication().getName(); Member member = memberRepository.findMemberByUsername(username); ListOperations<String, String> vo = redisTemplate.opsForList(); // 카테고리 리스트 List<String> getCategories = categories.stream() .map(m -> URLDecoder.decode(m, StandardCharsets.UTF_8)) .collect(Collectors.toList()); // 주변 동네 리스트 // Redis의 특징 중 하나인 자료구조 지원 기능을 사용해 List 형식으로 편의성을 높임 List<String> areaList = vo.range(member.getArea() + "::List", 0L, -1L); // 사용자 차단 리스트 List<String> blockList = blockRepository.findAllByMemberNickname(member.getNickname()).stream() .map(Block::getToMember) .collect(Collectors.toList()); List<BoardListResponseDto> result = boardRepository.findAll() .stream() .filter(board -> areaList.contains(board.getArea()) && getCategories.contains(board.getCategory()) && !blockList.contains(board.getMember().getNickname())) .map(BoardListResponseDto::toDto) .sorted(Comparator.comparing(BoardListResponseDto::getId, Comparator.reverseOrder())) .collect(Collectors.toList()); stopWatch.stop(); log.info(stopWatch.prettyPrint()); return result; }기존 조회 로직 Repository
public interface BoardRepository extends JpaRepository<Board, Long> { @Override List<Board> findAll(); }
백만개 데이터에 대한 조회 테스트 To One 타입이 1개, To Many 타입 컬렉션이 2개 존재할 때 최적화를 하지 않고 실행해본 결과
백만 개 데이터를 조회하는데 총 232초라는 시간이 소요되었고, 데이터를 객체로 변경하는 과정인 역직렬화(deserialization)는 디스크에 저장된 데이터를 읽거나, 네트워크를 통해 전송된 데이터를 받아서 메모리에 재구축하는 것입니다. 그렇기에 백만 개의 데이터를 역직렬화하는 시간과 함께 N+1 문제로 인한 쿼리 또한 매우 많이 발생했습니다.
N+1 문제란 간단하게 설명하고 넘어가자면
조회된 부모의 수만큼 자식 테이블의 쿼리가 추가 발생해
쿼리 1번으로 N건을 가져왔는데, 관련 컬럼을 얻기 위해 쿼리를 N번 추가 수행하는 현상입니다.
즉, 하위 (자식)엔티티들을 첫 쿼리 실행 시 한 번에 가져오지 않고 Lazy Loading으로 필요한 곳에서 사용되어 쿼리가 실행될 때 발생하는 문제를 JPA의 N+1 문제라고 합니다.
아래는 조회 대상인 Board의 수가 3개일 때를 예로 든 쿼리로
전체 게시글(3개)을 조회하기 위해 모든 데이터를 조회하는 findAll을 실행하면
부모인 Board 1번
자식인 BoardAlbums 3번,
자식인 Comments 3번
총 7번의 쿼리가 발생합니다.
Hibernate: # 부모( Board ) 조회 1번 select board0_.board_id as board_id1_2_, board0_.area as area2_2_, board0_.category as category3_2_, board0_.content as content4_2_, board0_.create_date as create_d5_2_, board0_.member_member_id as member_11_2_, board0_.read as read6_2_, board0_.thumbnail as thumbnai7_2_, board0_.thumbnail_id as thumbnai8_2_, board0_.title as title9_2_, board0_.update_date as update_10_2_ from board board0_ Hibernate: # 자식( BoardAlbum ) 조회 1번 select boardalbum0_.board_board_id as board_bo4_3_0_, boardalbum0_.board_album_id as board_al1_3_0_, boardalbum0_.board_album_id as board_al1_3_1_, boardalbum0_.board_board_id as board_bo4_3_1_, boardalbum0_.filename as filename2_3_1_, boardalbum0_.url as url3_3_1_ from board_album boardalbum0_ where boardalbum0_.board_board_id=? Hibernate: # 자식( Comment ) 조회 1번 select comments0_.board_board_id as board_bo6_6_0_, comments0_.comment_id as comment_1_6_0_, comments0_.comment_id as comment_1_6_1_, comments0_.board_board_id as board_bo6_6_1_, comments0_.content as content2_6_1_, comments0_.create_date as create_d3_6_1_, comments0_.nickname as nickname4_6_1_, comments0_.update_date as update_d5_6_1_ from comment comments0_ where comments0_.board_board_id=? Hibernate: # 자식( BoardAlbum ) 조회 2번 select boardalbum0_.board_board_id as board_bo4_3_0_, boardalbum0_.board_album_id as board_al1_3_0_, boardalbum0_.board_album_id as board_al1_3_1_, boardalbum0_.board_board_id as board_bo4_3_1_, boardalbum0_.filename as filename2_3_1_, boardalbum0_.url as url3_3_1_ from board_album boardalbum0_ where boardalbum0_.board_board_id=? Hibernate: # 자식( Comment ) 조회 2번 select comments0_.board_board_id as board_bo6_6_0_, comments0_.comment_id as comment_1_6_0_, comments0_.comment_id as comment_1_6_1_, comments0_.board_board_id as board_bo6_6_1_, comments0_.content as content2_6_1_, comments0_.create_date as create_d3_6_1_, comments0_.nickname as nickname4_6_1_, comments0_.update_date as update_d5_6_1_ from comment comments0_ where comments0_.board_board_id=? Hibernate: # 자식( BoardAlbum ) 조회 3번 select boardalbum0_.board_board_id as board_bo4_3_0_, boardalbum0_.board_album_id as board_al1_3_0_, boardalbum0_.board_album_id as board_al1_3_1_, boardalbum0_.board_board_id as board_bo4_3_1_, boardalbum0_.filename as filename2_3_1_, boardalbum0_.url as url3_3_1_ from board_album boardalbum0_ where boardalbum0_.board_board_id=? Hibernate: # 자식( Comments ) 조회 3번 select comments0_.board_board_id as board_bo6_6_0_, comments0_.comment_id as comment_1_6_0_, comments0_.comment_id as comment_1_6_1_, comments0_.board_board_id as board_bo6_6_1_, comments0_.content as content2_6_1_, comments0_.create_date as create_d3_6_1_, comments0_.nickname as nickname4_6_1_, comments0_.update_date as update_d5_6_1_ from comment comments0_ where comments0_.board_board_id=?1개를 조회했을 때 3번,
3개를 조회했을 때 7번,
10개를 조회했을 때 21번,
...
즉 게시글 N개 * 2 +1 만큼의 쿼리가 발생함을 알 수 있었습니다.
해당 글의 더미 데이터처럼 1000000건의 데이터라고 쳤을 때는 2000001번의 쿼리가 발생하는 만큼 사용자가 많아져
게시글이 많아졌을 때의 비용이 매우 비싸짐을 예상할 수 있습니다.
하지만 두 가지 이유 중 하나인 N+1 이슈를 해결하는 과정 ( 이전 포스팅 ) 에서 페치 조인을 통해
쿼리를 줄여 데이터 최적화를 할 수 있음을 알게 되었습니다. 채택한 방법은 @Entity Graph 어노테이션입니다.@Entity Graph는
Entity Graph 또한 fetch join으로
@Entity Graph 어노테이션을 Repository의 메소드에 작성하고attributePaths ={} 내부에 가져올 Entity 필드를 지정하면 지정된 Entity들을 Eager 조회로 가져와 실행합니다.
일반적 Join Fetch와 같이 Entity 필드의 하위 Entity 또한 가져올 수 있습니다.
다음과 같이 코드를 변경해 1차 데이터 최적화를 진행했습니다.
public interface BoardRepository extends JpaRepository<Board, Long> { @Override @EntityGraph(attributePaths = {"member", "boardAlbums", "comments"}) List<Board> findAll(); }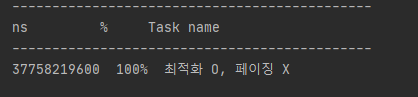
백만개 데이터에 대한 1차 최적화 진행 후 조회 테스트 페치 조인을 통한 쿼리 최적화로 232초 -> 37초로 조회 시간이 많이 줄어든 모습을 확인할 수 있었지만 아직까지도 오랜 시간이 걸리는 근본적인 문제는 백만 개가 넘는 데이터를 한 번에 내려주는 서버가 문제라고 생각합니다.
제작 중 프로젝트는 이렇게 대용량 데이터를 한 번에 내려주는 서버로 구성할 필요가 없다고 생각하기 때문에 페이징을 통해 데이터를 나눠 내려주기로 했습니다.
페이징 적용
Repository 로직을 다음과 같이 변경합니다 .
1. 최신 글부터 보기 위한 order by desc를 통한 역순 정렬
2. List 타입을 Page 타입으로 변경
public interface BoardRepository extends JpaRepository<Board, Long> { @Override @Query("SELECT b FROM Board b order by b.id desc ") @EntityGraph(attributePaths = {"member", "boardAlbums", "comments"}) Page<Board> findAll(Pageable pageable); }Pageable = PageRequest.of( offset, limit ) limit은 20으로 값을 준 뒤 데이터를 조회한 결과
Hibernate: select board0_.board_id as board_id1_2_0_, member1_.member_id as member_i1_10_1_, comments2_.comment_id as comment_1_6_2_, boardalbum3_.board_album_id as board_al1_3_3_, board0_.area as area2_2_0_, board0_.category as category3_2_0_, board0_.content as content4_2_0_, board0_.create_date as create_d5_2_0_, board0_.member_member_id as member_11_2_0_, board0_.read as read6_2_0_, board0_.thumbnail as thumbnai7_2_0_, board0_.thumbnail_id as thumbnai8_2_0_, board0_.title as title9_2_0_, board0_.update_date as update_10_2_0_, member1_.area as area2_10_1_, member1_.nickname as nickname3_10_1_, member1_.password as password4_10_1_, member1_.role as role5_10_1_, member1_.username as username6_10_1_, comments2_.board_board_id as board_bo6_6_2_, comments2_.content as content2_6_2_, comments2_.create_date as create_d3_6_2_, comments2_.nickname as nickname4_6_2_, comments2_.update_date as update_d5_6_2_, comments2_.board_board_id as board_bo6_6_0__, comments2_.comment_id as comment_1_6_0__, boardalbum3_.board_board_id as board_bo4_3_3_, boardalbum3_.filename as filename2_3_3_, boardalbum3_.url as url3_3_3_, boardalbum3_.board_board_id as board_bo4_3_1__, boardalbum3_.board_album_id as board_al1_3_1__ from board board0_ left outer join member member1_ on board0_.member_member_id=member1_.member_id left outer join comment comments2_ on board0_.board_id=comments2_.board_board_id left outer join board_album boardalbum3_ on board0_.board_id=boardalbum3_.board_board_id order by board0_.board_id desc페이징 자체는 원하던 대로 동작했지만 실행된 쿼리를 확인해보니 limit 조건이 보이지 않았습니다.
다시 로그와 쿼리를 확인하던 중
o.h.h.internal.ast.QueryTranslatorImpl : HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!위와 같은 경고를 볼 수 있었는데 이 경고문은 컬렉션 타입을 페치 조인 한 뒤 페이징을 진행하면
메모리 단에서 페이징을 처리하기 때문에 OutofMemory 오류로 인해 장애가 발생할 확률이 높아 매우 위험함을 알려주는 경고문이었습니다.
limit 절이 보여지지 않은 이유는 컬렉션 타입을 조인했을 때 데이터의 수가 변할 가능성이 존재해 몇 개의 데이터를 가져와야하는지 명확하게 알려줄 수 없기 때문이었습니다.
문제점
JPA에서 paging을 하게 되면 일대다 테이블을 조인했을 때 데이터의 수가 변하기 때문에 몇 개의 데이터를 가져와야하는지 명확하게 알려줄 수 없기 때문에 위처럼 limit 절이 보여지지 않았고, OneToMany, ManyToMany 같은 컬렉션 관계는 fetch join이 불가능합니다. 그래서 JPA에서는 paging을 하면서 컬렉션 관계를 fetch join 하는 것 자체를 동작하지 않도록 막아두었습니다.
그렇다면 어떻게 조회 성능을 최적화할 수 있을까?
조회 시 성능 최적화를 위해
컬렉션이 아닌 데이터는 조인을 통해 묶어서 가져와 성능 최적화를 진행하고
컬렉션 타입인 데이터는 hibernate의 default_batch_fetch_size를 통해
In 절로 쿼리를 날려 데이터를 가져와 성능 최적화를 진행하기로 했습니다.
1. ToOne( One To One, Many To One )관계는 모두 페치 조인
( 데이터가 예측할 수 없이 증가되는 현상이 발생하지 않아 페이징 쿼리에 영향을 주지 않는다 )2. 컬렉션은 모두 지연 로딩으로 조회
3. 지연 로딩 성능 최적화를 위해 BatchSize를 글로벌 설정해 프록시 객체를 설정한 size만큼 IN 쿼리로 조회
Board와 To One 관계인 Member는 페치 조인을 통해,
Board와 To Many 관계인 Comment와 BoardAlbum은 Batch를 통해 최적화하기 위해
기존의 repository의 컬렉션 페치 조인을 제거한 뒤 yml에 BatchSize를 글로벌 적용해주었습니다.
BoardRepository
public interface BoardRepository extends JpaRepository<Board, Long> { @Override @Query("SELECT b FROM Board b order by b.id desc ") @EntityGraph(attributePaths = {"member"}) Page<Board> findAll(Pageable pageable); }application.yml
jpa: properties: hibernate: default_batch_fetch_size: 1000사이즈를 1000으로 정한 이유는 이 전략을 사용하면 SQL IN 절을 사용하는데, IN 절 파라미터를 1000으로 잡으면 한 번에 1000개를 DB에서 애플리케이션에 불러오므로 DB에 순간 부하가 발생하고 DB마다 다르지만 최대 1000개로 잡아놓는 것이 성능상 가장 좋다고 알고 있어 1000개로 지정했습니다.
장점
1. 쿼리 호출 수가 1 + 1 로 최적화
2. 조인보다 DB 데이터 전송량이 최적화 ( 데이터를 각각 조회해 중복도 존재하지 않음 )3. 페치 조인과 비교했을 때 쿼리 호출 수는 증가하지만 DB 데이터 전송량 자체는 감소
4. 컬렉션은 페치 조인을 사용했을 때 페이징이 불가능하지만 이 방법은 페이징이 가능
페이징 후 조회 속도
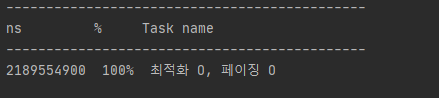
백만개 데이터에 대해 최적화, 페이징 후 조회 테스트 페이징을 적용하기 전 37초 -> 2.1초로 다시 한번 많이 줄어든 조회 시간을 확인할 수 있었습니다.
하지만 최신 순으로 데이터를 조회할 때 ORDER BY DESC 정렬을 사용하는데
백만 개 기준 모든 페이지의 조회는 페이지당 약 2초가 걸렸으나 이 또한 매우 긴 시간이기에 더 줄이는 방법을 생각해보았습니다.
더 나은 방법의 강구
생각해낸 방법 중 하나는 컬렉션 타입인 댓글과 앨범의 수를 세는 카운트 쿼리가 문제가 되어 속도가 느린 것인가 생각이 들어 컬렉션 타입을 모두 제거한 뒤 시도해보았음에도 속도가 더 이상 개선되지 않았습니다.
데이터 최적화 -> 페이징을 거쳤을 때 최종적으로 페이지당 약 2초의 조회 성능을 가지게 되었습니다.
하지만 데이터를 조회할 때 이 정도의 시간이 걸린다면 만족스러운 사용이 불가능하다고 생각합니다.
그렇기에 한번 더 조회 성능을 끌어올리고자 인덱스를 도입하기로 했습니다.
그렇다면 모든 게시글을 조회하는 페이징에선 어떤 컬럼을 인덱스로 적용해야 하는지 생각해보았고
생성 시간에 대해 내림차순 인덱스를 적용한다면 역순으로 정렬된 인덱스 테이블을 검색해 보다 빠르게 조회할 수 있을 것이다 생각이 들어 테스트해본 결과 의미 있는 결과를 이끌어낼 수 있었습니다.
여러 가지 대상으로 비교해본 성능 개선 기록
모든 대상의 비교를 위해
1. 최적화
2. 페이징
3. 타입 List, Page, Slice
4. 인덱스
5. JPQL 한계 돌파
위 4가지 방법들을 하나씩 적용해가며 테스트를 진행했습니다.
사전 작업 : 인덱스 추가
먼저 인덱스를 사용하는 비교군을 위해 Board Entity에 다음과 같이 인덱스를 설정해주었습니다.
..// @Table(name = "board", indexes = @Index(name = "createDate",columnList = "createDate DESC")) public class Board { ..// }성능 테스트 시작
대상
최적화 X, 페이징 X, 타입 List, 인덱스 X
최적화 O, 페이징 X, 타입 List, 인덱스 X최적화 O, 페이징 O, 타입 Page, 인덱스 X
최적화 O, 페이징 O, 타입 Page, 인덱스 O
최적화 O, 페이징 O, 타입 Slice, 인덱스 O최적화 O, 페이징 O, 타입 List, 인덱스 O, Querydsl
측정 방법 : Spring Stop Watch
기준 : Board 백만 개
최적화 : To One 관계 -> fetch Join, To Many 관계 ->BatchSize 적용
최적화 X, 페이징 X, 타입 List, 인덱스 X
@Query("SELECT b FROM Board b ORDER BY b.id DESC") List<Board> findAllBoard(); //Entity Graph, default_batch_fetch_size 미적용최적화 X, 페이징 X, 타입 List, 인덱스 X ->232초 최적화 O, 페이징 X, 타입 List, 인덱스 X
@Override @Query("SELECT b FROM Board b ORDER BY b.id DESC ") @EntityGraph(attributePaths = {"member","boardAlbums","comments"}) List<Board> findAll(); //Entity Graph, default_batch_fetch_size : 1000 적용최적화 O, 페이징 X, 타입 List, 인덱스 X -> 37초 최적화 O, 페이징 O, 타입 Page, 인덱스 X
@Override @Query("SELECT b FROM Board b ORDER BY b.id DESC ") @EntityGraph(attributePaths = {"member"}) Page<Board> findAll(Pageable pageable); //Entity Graph, default_batch_fetch_size : 1000 적용최적화 O, 페이징 O, 타입 Page, 인덱스 X -> 2.1초 최적화 O, 페이징 O, 타입 Page, 인덱스 O
@Query("SELECT b FROM Board b WHERE b.createDate < :time") @EntityGraph(attributePaths = {"member"}) Page<Board> findBoards(Pageable pageable, @Param("time") LocalDateTime time); //Entity Graph, default_batch_fetch_size : 1000 적용 //createDate ( 생성시간 )기준 내림차순 인덱스 적용
최적화 O, 페이징 O, 타입 Page, 인덱스 O -> 1.8초 인덱스를 적용해도 생각보다 조회 시간이 오래 걸림을 확인할 수 있었는데
이를 해결하기 위한 방법을 찾아보던 중 Page와 비슷한 Slice를 알게 되었습니다.
Page, Slice의 차이점
먼저 위에서 사용한 Page 반환형은 크게 아래와 같은 특징을 가지고 있습니다.
1. 사용 가능한 데이터의 총 개수 및 전체 페이지 수를 알 수 있다.
2. 총개수를 알아내기 위해 추가적으로 카운트 쿼리가 실행된다.
Slice는 다음과 같은 특징을 지니고 있습니다.
1. 다음 Slice (page)가 있는지의 여부만 알고 있다.
2. 추가적인 카운트 쿼리가 실행되지 않는다.
3. 그렇기에 데이터 셋이 큰 경우 Slice를 사용하는 것이 성능상 유리하다.
추가적인 카운트 쿼리가 실행되지 않기에 데이터가 많을수록 성능이 좋아질 것이라 판단되어 마지막 비교 대상의
타입을 Slice로 정하고 실행해본 결과입니다.
최적화 O, 페이징 O, 타입 Slice, 인덱스 O
@Query("SELECT b FROM Board b WHERE b.createDate < :time") @EntityGraph(attributePaths = {"member"}) Slice<Board> findBoards(Pageable pageable, @Param("time") LocalDateTime time); //Entity Graph, default_batch_fetch_size : 1000 적용 //createDate ( 생성시간 )기준 내림차순 인덱스 적용
최적화 O, 페이징 O, 타입 Slice, 인덱스 O -> 0.03초 최적화 O, 페이징 O, 타입 List, 인덱스 O, Querydsl
H2 Database To MySQL
h2 database를 사용하면서 콘솔을 통해 실행 계획을 볼 수 있었지만 어색하고 잘 읽히지 않기도 하고
테스트를 할 때 백만 개의 데이터를 계속 넣어주는 것이 시간도 오래 걸려 비효율적이라 생각해
h2 -> MySQL 변경, 쿼리를 작성해 인덱스를 제대로 타는지 검사하고 작성된 쿼리를
Querydsl을 사용한 동적 쿼리 작성 조회 성능 최적화한 결과입니다.Slice가 빠르지만 사용하지 않은 이유는 변경한 로직이 기존 로직에 비해 빠르고 마지막 페이지로 가까워질수록 느려졌던 조회 또한 10배 이상 빨라진 결과를 반환합니다.
또한 Slice를 사용했을 때 일반적 페이징을 구현하기 까다롭고, 프론트 단에서 처리해줄게 너무 늘어나는 단점이 있었는데, 최종적으로 빠르고 편한 로직으로 변경이 가능했습니다.
조회할 Board의 id만을 위에서 설정한 create_date를 사용하지 않고
클러스터 인덱스인 board.id를 쿼리에 사용되는 모든 속성이 인덱스로 구성되어 인덱스 테이블로만 데이터를 구할 수 있어 속도가 빠른 커버링 인덱스를 사용해 빠르게 id만을 조회합니다.
그 후 구해진 id리스트를 사용해 정보를 구한 뒤 반환하는 로직으로 변경
쿼리가 두 부분으로 나뉘어진 이유는
SELECT * FROM Board as b JOIN (SELECT id FROM Board WHERE 조건문 ORDER BY id DESC OFFSET 페이지번호 LIMIT 페이지사이즈) as tempBoard on tempBoard.id = b.idJPQL, Querydsl - JPA에서는 위 코드와 같이 FROM 절의 서브쿼리를 지원하지 않기 때문에 이를 우회하기 위해 두 부분으로 나누어 사용했습니다. ( 참고 https://jojoldu.tistory.com/529 )
List<Long> ids 를 구하는 쿼리는 커버링 인덱스로 대상을 조회합니다
return 되는 쿼리는 커버링 인덱스로 구한 id로 실제 데이터를 조회합니다
BoardQueryRepository
public List<QBoardDto> findBoards(int off, int size){ List<Long> ids = queryFactory .select(board.id) .from(board) .orderBy(board.id.desc()) .limit(size) .offset(off * size) .fetch(); return queryFactory .select(Projections.constructor(QBoardDto.class, board.id, board.area, board.title, board.content, board.member.nickname, board.updateDate, board.thumbnail, board.category, board.comments.size(), board.boardAlbums.size() )) .from(board) .where( board.id.in(ids) ) .limit(size) .fetch(); }
최적화 O, 페이징 O, 타입 List, 인덱스 O, Querydsl 첫 페이지 -> 0.05초 
최적화 O, 페이징 O, 타입 List, 인덱스 O, Querydsl 마지막 페이지 -> 0.2초 최종 조회 로직public Result paging(int offset, List<String> categories) { Member member = findMemberByUsername(); ListOperations<String, String> vo = redisTemplate.opsForList(); List<String> getCategories = categories.stream() .map(m -> URLDecoder.decode(m, StandardCharsets.UTF_8)) .collect(Collectors.toList()); List<String> al = vo.range(member.getArea() + "::List", 0L, -1L); List<String> blockList = blockRepository.findAllByMemberNickname(member.getNickname()).stream() .map(Block::getToMember) .collect(Collectors.toList()); List<QBoardDto> list = queryRepository.ff(offset,20).stream() .filter(board -> al.contains(board.getArea()) && getCategories.contains(board.getCategory()) && !blockList.contains(board.getNickname())) .collect(Collectors.toList()); int totalPage = boardRepository.boardCount()/20; return new Result(list, !list.isEmpty(),totalPage); }최종 조회 로직
기존에 사용하던 filter 방식은 페이지 수가 제대로 노출되지 않을 가능성이 다분 ( 가져온 20개의 데이터에 대해 Filtering하기 때문에 20개보다 적은 게시물이 출력될 수 있고 조건에 맞는 게시글 전체 페이지 수랑 맞지 않음 )했기 때문에 데이터베이스에서 처리하도록 변경
nickname, area, category를 Index로 지정해 커버링 인덱스로 가져옴
1. Not in을 통한 블락 대상인지 확인 ( blockList )
2. In을 통한 지역 확인 ( areaList )
3. In을 통한 카테고리 확인 ( CategoryList )
인덱스 그룹

QueryRepository.findBoards
public List<QBoardDto> findBoards(int off, int size, String nickname, List<String> blockList,List<String> areaList, List<String> categoryList) { List<Long> ids = queryFactory .select(board.id) .from(board) .where(eqNickname(nickname), inBlockList(blockList), inAreaList(areaList), inCategoryList(categoryList)) .orderBy(board.id.desc()) .limit(size) .offset(off * size) .fetch(); if (CollectionUtils.isEmpty(ids)) { return new ArrayList<>(); } return queryFactory .select(Projections.constructor(QBoardDto.class, board.id, board.area, board.title, board.content, board.nickname, board.updateDate, board.thumbnail, board.category, board.boardAlbums.size(), board.comments.size() )) .from(board) .where( board.id.in(ids) ) .orderBy(board.id.desc()) .fetch(); }또한 Redis에 장애가 발생해 주변 동네 areaList를 조회할 수 없다면 직접 DB 데이터를 조회할 수 있도록 코드 변경
boardService.paging
List<String> areaList = vo.range(getMembersArea + "::List", 0L, -1L); if (areaList.isEmpty()) { areaList = memberService.setNearArea(getMembersArea); vo.leftPushAll(getMembersArea + "::List", areaList); }변경된 전체 코드 ( DB에서 필터링하기 때문에 반복문 제거 )
boardService
public Result paging(int page, List<String> categories, String nickname) { StopWatch stopWatch = new StopWatch(); stopWatch.start("paging 시작"); Member member = findMemberByUsername(); String getMembersArea = member.getArea(); ListOperations<String, String> vo = redisTemplate.opsForList(); //카테고리 리스트 List<String> categoryList = categories.stream() .map(m -> URLDecoder.decode(m, StandardCharsets.UTF_8)) .collect(Collectors.toList()); //주변 동네 리스트 List<String> areaList = vo.range(getMembersArea + "::List", 0L, -1L); //없을 경우 DB에서 조회 후 Redis에 저장 if (areaList.isEmpty()) { areaList = memberService.setNearArea(getMembersArea); vo.leftPushAll(getMembersArea + "::List", areaList); } //차단 사용자 리스트 List<String> blockList = member.getBlocks().stream() .map(Block::getToMember) .collect(Collectors.toList()); //필터링 후 데이터 조회 List<QBoardDto> QBoardList = queryRepository.findBoards(page, 20, nickname, blockList, areaList, categoryList); int totalPage = boardRepository.boardCount() / 20; stopWatch.stop(); log.info(""+ stopWatch.prettyPrint()); return new Result(QBoardList, totalPage); }BoardQueryRepository
public List<QBoardDto> findBoards(int off, int size, String nickname, List<String> blockList,List<String> areaList, List<String> categoryList) { List<Long> ids = queryFactory .select(board.id) .from(board) .where(eqNickname(nickname), inBlockList(blockList), inAreaList(areaList), inCategoryList(categoryList)) .orderBy(board.id.desc()) .limit(size) .offset(off * size) .fetch(); if (CollectionUtils.isEmpty(ids)) { return new ArrayList<>(); } return queryFactory .select(Projections.constructor(QBoardDto.class, board.id, board.area, board.title, board.content, board.nickname, board.updateDate, board.thumbnail, board.category, board.boardAlbums.size(), board.comments.size() )) .from(board) .where( board.id.in(ids) ) .orderBy(board.id.desc()) .fetch(); } BooleanExpression eqNickname(String nickname) { if (nickname == null) { return null; } return board.nickname.like(nickname+"%"); } BooleanExpression inBlockList(List<String> blockList){ if(blockList == null){ return null; } return board.nickname.notIn(blockList); } BooleanExpression inAreaList(List<String> areaList){ if(areaList== null){ return null; } return board.area.in(areaList); } BooleanExpression inCategoryList(List<String> categoryList){ if(categoryList==null){ return null; } return board.category.in(categoryList); }실제 쿼리
Hibernate: select member0_.member_id as member_i1_9_, member0_.area as area2_9_, member0_.nickname as nickname3_9_, member0_.password as password4_9_, member0_.role as role5_9_, member0_.username as username6_9_ from member member0_ where member0_.username=? Hibernate: select blocks0_.member_member_id as member_m3_1_1_, blocks0_.follow_id as follow_i1_1_1_, blocks0_.follow_id as follow_i1_1_0_, blocks0_.member_member_id as member_m3_1_0_, blocks0_.to_member as to_membe2_1_0_ from block blocks0_ where blocks0_.member_member_id=? Hibernate: select board0_.board_id as col_0_0_ from board board0_ where 1<>2 and ( board0_.area in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) ) and ( board0_.category in ( ? , ? , ? , ? , ? , ? ) ) order by board0_.board_id desc limit ? Hibernate: select board0_.board_id as col_0_0_, board0_.area as col_1_0_, board0_.title as col_2_0_, board0_.content as col_3_0_, board0_.nickname as col_4_0_, board0_.update_date as col_5_0_, board0_.thumbnail as col_6_0_, board0_.category as col_7_0_, (select count(boardalbum1_.board_board_id) from board_album boardalbum1_ where board0_.board_id = boardalbum1_.board_board_id) as col_8_0_, (select count(comments2_.board_board_id) from comment comments2_ where board0_.board_id = comments2_.board_board_id) as col_9_0_ from board board0_ where board0_.board_id in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) order by board0_.board_id desc문제 발생 ..
문제점
1. DB에서 필터링을 함으로 데이터 불일치를 해결했으나 마지막 페이지로 갈수록 느려지는 현상 발생
2. 전체 페이지 수를 구하는 Count문에서 1초의 시간이 걸림
필터링 데이터 - List<String> nickname, List<String> area, List<String> category
인덱스 - board_id, nickname, area, category
실행계획 - using where, using index, backward index scan

Backward index scan Backward index scan이 문제가 되는 것으로 생각해
MySQL 8버전부터 지원해주는 Desending Index를 도입하고자 함
현재 MyISAM 엔진이랑 Desending Index 사용이 불가해
InnoDB 엔진으로 테이블 엔진을 변경한 뒤
create index board_indexes on board (board_id desc, nickname desc, area desc, category desc) 인덱스 생성

인덱스 컬럼과 쿼리가 같은 상황에서
1. MyISAM 엔진으로 DB필터링 진행했을 때 ( Using Where, Using Index, Backward index scan )
결과 -> 마지막 페이지 약 4초 소요

2. InnoDB 엔진으로 DB필터링 진행했을 때 ( Using Where, Using Index )
결과 -> 마지막 페이지 1초 소요

InnoDB의 Desending Index를 통해 조회 성능을 향상시킬 수 있었음.
하지만 전체 페이지 수를 구하는 쿼리를 쓸 때 속도 저하가 발생
IN 절 조건문 3개 기준 count 쿼리 소요 시간
MyISAM count 쿼리 -> 0.7초
InnoDB count 쿼리 -> 1초
데이터 결과
데이터는 모두 정상적으로 필터링 됨을 확인했음
MyISAM 엔진 -> 0.7 ~ 5초
InnoDB 엔진 -> 1초 ~ 2초
카운트 쿼리를 어떻게 향상시켜야 할지 방법을 찾는중입니다..
쿼리 전문
Hibernate: select blocks0_.member_member_id as member_m3_1_1_, blocks0_.follow_id as follow_i1_1_1_, blocks0_.follow_id as follow_i1_1_0_, blocks0_.member_member_id as member_m3_1_0_, blocks0_.to_member as to_membe2_1_0_ from block blocks0_ where blocks0_.member_member_id=? Hibernate: select board0_.board_id as col_0_0_ from board board0_ where 1<>2 and ( board0_.area in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) ) and ( board0_.category in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) ) order by board0_.board_id desc limit ? Hibernate: select board0_.board_id as col_0_0_, board0_.area as col_1_0_, board0_.title as col_2_0_, board0_.content as col_3_0_, board0_.nickname as col_4_0_, board0_.update_date as col_5_0_, board0_.thumbnail as col_6_0_, board0_.category as col_7_0_, (select count(boardalbum1_.board_board_id) from board_album boardalbum1_ where board0_.board_id = boardalbum1_.board_board_id) as col_8_0_, (select count(comments2_.board_board_id) from comment comments2_ where board0_.board_id = comments2_.board_board_id) as col_9_0_ from board board0_ where board0_.board_id in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) order by board0_.board_id desc Hibernate: select count(board0_.board_id) as col_0_0_ from board board0_ where 1<>2 and ( board0_.area in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) ) and ( board0_.category in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) )No offset으로 한다면 모든 페이지가 0.0x초 대로 나오기도 하고
서비스 특성상 앞쪽의 페이지만 볼 가능성이 높아 효율적이라고 생각은 들지만
기존 페이징에서의 성능 개선 목적이고 개인적으로 웹에서는 No offset은 불편한 것 같아 제외했고
페이징에서는 페이징 자체도 중요하지만 카운트 쿼리의 처리가 관건인 것같음.. 후에 다시 추가할 예정
결과
페이징을 통한 조회 성능 개선은 다음과 같이 진행되었습니다.
최적화 X, 페이징 X, 타입 List, 인덱스 X-> 232초
최적화 O, 페이징 X, 타입 List, 인덱스 X -> 37초최적화 O, 페이징 O, 타입 Page, 인덱스 X-> 2.1초 ~ 2.3초
최적화 O, 페이징 O, 타입 Page, 인덱스 O-> 1.8초 ~ 2.1초
최적화 O, 페이징 O, 타입 Slice, 인덱스 O -> 0.04초 ~ 1.8초최적화 O, 페이징 O, 타입 List, 커버링 인덱스 O -> 0.005 ~ 0.2초
최종적으로 232초 -> 0.005 ~ 0.2초의 조회 성능이 개선되었음을 확인할 수 있었습니다.하지만 기존의 위 테스트는 사용자에게 보여줄 데이터 필터링 과정이 어플리케이션 단에서 일어나 데이터 불일치가 발생할 수 있다는 단점이 있음을 알게되었고 DB 내부에서 필터링 처리하도록 변경해 테스트하고 가장 빠른 방법을 찾은
결과
MyISAM 엔진, 커버링 인덱스, Desending Index 사용 전 -> 0.005 ~ 4초
InnoDB 엔진, 커버링 인덱스, Desending Index 사용 후 -> 0.005 ~ 1초
-> InnoDB 엔진으로 Desending Index를 적용하면 최신 순으로 데이터를 가져오는 페이징에서 Backward index scan 보다 더 유리함을 알게되었음
IN 절 조건문 3개 기준 count 쿼리 소요 시간
MyISAM 엔진 count, 커버링 인덱스 , Desending Index -> 보통 0.4초 ~ 0.7초 소요
InnoDB 엔진 count , 커버링 인덱스 , Desending Index -> 보통 1초 소요
결국 조건에 맞는 게시글의 총 페이지 수를 구하려다 보니 결국 오래걸리게 되네요 . . 어렵습니다 //
최종적으로 232초 -> 1초 ~ 2초의 조회 성능을 가지게 되었음 ,,?
결론
마지막 페이지에 다가갈수록 오래 걸리는 것은 만족스럽지 않으나
사용자 입장일 때 보통 초반부 페이지만을 확인하는 경향이 있고 물품을 사고, 팔고 어떤 행동을 같이할 사람을
모집하는 ShMarket 서비스 특성상 초반부 페이지가 중요하다고 생각되어 어느 정도 만족하려 했으나
성능 개선을 기록하는 것이니만큼 성능 최적화를 조금 더 해보고 싶은 생각으로 다른 방법을 강구하던 중 변경된 로직으로 후반부 페이지 또한 평균 0.2초의 조회가 가능해졌습니다.
하지만.. 조건에 맞는 게시글의 페이지 수를 구하고 데이터 불일치 문제를 해결하고자 DB 단에서 필터링을 진행하고 전체 페이지 수를 구하는 COUNT 쿼리 때문에 다시 1초~2초로 늘어나버렸네요 다른 방법 또한 생각해봐야겠습니다
1. 트리거 통해 row 테이블을 관리한다?
2. 첫 조회 카운트 쿼리를 캐싱한다?
3. 페이지 이동이 클릭되었을 때만 페이지 쿼리를 날린다?
4. No offset을 도입한다
'ShMarket' 카테고리의 다른 글
ShMarket - Redis 캐싱 전략과 장애 대비 (0) 2021.07.31 ShMarket - 푸시 알림과 성능 개선 (1) 2021.07.05 ShMarket - 이슈 #1 N+1문제와 그로 파생되는 문제 해결 (0) 2021.06.20 ShMarket - 프로젝트 소개 (0) 2021.06.19